Testing a Hypothesis¶
H1: Are pieces in the Polish folksong corpus more "rhythmically complex" than another corpus? "Complex" is obviously a pretty loaded term, and it isn't really not something that can be formalized, but "variability" might be thought of as a proxy for complexity.
The normalized variability index (nPVI) has been used extensively over the past few years as a way of examining rhythmic variability in melodies. It's adapted from linguistics (Grabe and Low, 2003) looking at the rhythmic variability of speech. Patel and Daniele (2004) argued that the variability of melodies can be correlated with the composer's native language.
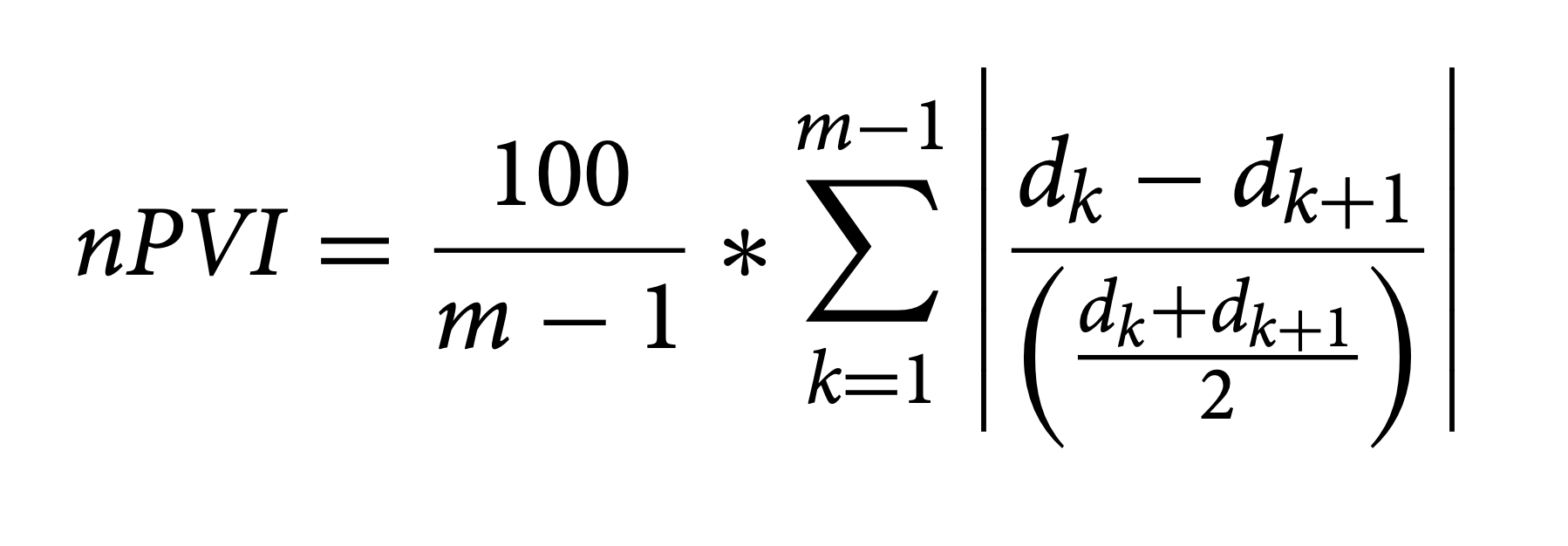
Let's break down how we might break this down into a function we could implement.